<早稲田大学データ科学センターの考えるデータサイエンス>
データサイエンスとは何かについては,その成立過程の歴史はあまり明確でなく[注1],その定義も様々で統一的定義は見受けられない.
一般には,統計学をはじめ人工知能,機械学習,データ分析等の学問分野をの集合として定義が多く見られる.その上,人工知能や機械学習それぞれの定義[注2]も多様なため,両者の包含関係,データサイエンスとの相互関係さえも立場によって違いがあり,個々の定義すら曖昧な分野を寄せ集めた定義ではデータサイエンスの学問分野としての本質を捉えるには不十分であろう.
さらに,データサイエンスは,情報処理,通信,数学など広範な学問・技術とも密接な関係にあり,それらも含めるとその領域は極めて広大で,寄せ集め的定義を繰り返すだけでは発散する方向に向かいその本質に迫ることは不可能である.
また,上記の統計学,人工知能,機械学習,情報処理,通信等の学問と技術は常に進化しており,データサイエンスの本質を普遍的に定義することは,より難しいように思える.
データサイエンスの全学の教育研究を担う早稲田大学データ科学センター(以下センター)では,明確で本質的なデータサイエンス(データ科学)の定義を基盤として教育研究を行わなければならないと考えている.そこで一般的に考えられている定義とは全く別の視点から,データサイエンス(データ科学)を
「データからの論理的推論による意思決定の科学」
と定義している.
この定義では,データサイエンスを従来のような手法や技術の集合としての定義とは違い,思考の枠組みとして捉えている点に特徴がある.
この定義における「意思決定」は複数の選択肢の中から何らかの基準に基づいて選択を行う広い概念を意味し,「論理的推論」も数理論理学における演繹推論に限らず,後で述べる統計的推測や機械学習による予測などを含む広い概念となっている.
この定義は科学とは何かという問題とも深く関係している.
科学を目的や対象ではなくその方法,すなわち科学的方法から定義する立場がある[注3].
自然科学における科学的方法では,観測された現象(事実)を説明(記述)する体系(構造)の構築(広い意味の意思決定)を目指して,その論理的推論には統計学が重要な役割を担ってきた.
近年この科学的方法とその対象範囲に変化が生じてきている.
この科学的方法の拡張をデータ科学と捉えることが,先に挙げたセンターのデータ科学の定義となっており,データ科学をメタ科学と捉える解釈ともいえる.
また,今後も情報処理・通信の技術や論理的推論の理論の発展により,ますますデータの多様化が進み,意思決定の対象も拡大していったとしても,この定義は変わることなくデータ科学の本質を表している.
センターでは,思考のプロセスとしてデータ科学を定義しているため,データ科学の教育,データ科学を活用した研究のためには,そのプロセスを具体的な方法論として示す必要がある.
しかし,方法論に落とし込んだ場合,結局従来の統計学,AI,機械学習等の各手法の寄せ集めとなってしまっては意味がない.
そこでセンターでは,データ科学の意思決定プロセスを,データを入力とし意思決定を出力とする写像(関数)として論理的推論を図のように表現し,これを意思決定写像と呼んでいる.
意思決定写像として,データの定義域と意思決定の値域を限定しただけでは,論理的推論となる写像は構成されない.データ科学の場合は,
を適切に決めることによって,意思決定写像の論理的推論は数理的問題やアルゴリズムの解として表現可能となる.
この意思決定写像の入力である目的,設定,評価基準,データの定義域と,出力である意思決定の値域を適切に決めることで,統計学,AI,機械学習のすべての手法を体系的に表現可能であり統一的な理解が可能となる.
例として,線形回帰分析を表現した意思決定写像を図1に示す(参考文献[2] データ科学入門Ⅱ p.25 図2.10 より).
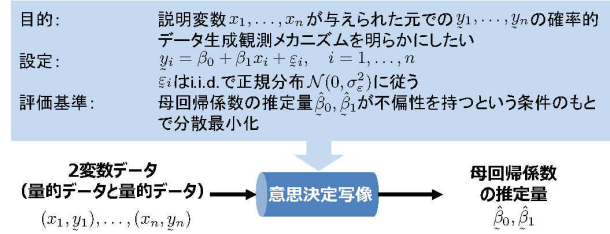
【図1. 線形回帰分析を表現した意思決定写像】
この図では,意思決定写像の入力は量的な2変数データで,出力は母回帰係数の推定量となっており,目的,設定,評価基準が以下となっていることが表現されている.
詳しくは,ライブラリデータ科学のデータ科学入門Ⅰ〜Ⅳを参照されたい.
センターでは,全学の教育研究を担うため,データ科学を「データからの論理的推論による意思決定の科学」の本質を意思決定の思考プロセスとし,そのプロセスの具体的な方法論を意思決定写像による統一的体系によって整理することで,様々な技術や方法を寄せ集めたものとは異なる教育と研究を行っている.
近年AIやデータサイエンスの発展は大きな社会変革をもたらしつつあるが,より本質的変革は,このデータからの論理的意思決定の思考プロセスを身につけた人材が,社会の様々な分野で活躍することによりもたらされるとも考えられる.
早稲田大学データ科学センターは,データ科学の本質的定義を基に統一的体系から人材育成と研究推進を担うセンターとして,これからも社会に貢献していきたいと考えている.
[注1] 学問分野での登場は,日本人を含む数名の研究者が1996年ぐらいに異なる文脈から使い始めたとされている.
[注2] 人工知能(AI: Artificial Intelligence)は,1956年のダートマス会議において,J. McCarthy, M. L. Minsky, N. Rochester, C. E. Shannonにより,人間の学習等の知的機能(知能)をコンピュータにより模倣することで,知能とは何かを探求する研究テーマとして提案された.しかし知能の模倣は結果として高度な情報処理機能を実現することになり,様々な応用への期待が高まり,人間についての科学的研究から工学的研究へと主目的がシフトしていった.
1959年には,データを与えることでコンピュータがあるタスクを自動的に行えるようにすることを目指す,機械学習(machine learning)の研究がA. L. Samuelによって提案された.この研究は人間の学習機能をコンピュータで模倣する試みであり,知能全体の模倣を目指すAIの一分野と捉えることができるが,機械学習においてもAIの目的の工学的なシフトと相まって,音声や画像のパターン認識等の工学的研究へと中心が移っていった.深層ニューラルネットワークはAIや機械学習の一つの手法であるが,近年はAIというとこの深層ニューラルネットのみを指す場合もあり,これらの用語について混乱も生じているようだ.
[注3] 科学的方法の定義はK. R. Poppeによる反証可能性を軸とする仮説を設定しデータで検証する仮説検証型や北川源四郎やJ. Grayのデータから仮説を生成する仮説帰納型,またそれらを融合したものなど様々な立場があるが,いずれもデータサイエンスとは密接な関係がある.
【参考文献】
[1] データ科学入門I (ライブラリ データ科学)サイエンス社 ISBN978-4-7819-1540-1
[2] データ科学入門Ⅱ (ライブラリ データ科学)サイエンス社 ISBN978-4-7819-1567-8
[3] データ科学入門Ⅲ(ライブラリ データ科学)サイエンス社 ISBN978-4-7819-1598-2
[4] データ科学入門Ⅳ (ライブラリ データ科学)サイエンス社 ISBN978-4-7819-1629-2
松嶋 敏泰 2026年3月作成
※松嶋 敏泰氏は2017年12月1日から2026年3月31日まで早稲田大学データ科学センター所長を務めた。
<データ科学教育プログラムの特徴>
早稲田大学は13の学部17の研究科、4の専門職大学院という幅広い学問領域を持つ私立総合大学であり,既に多くの学問領域においてデータ科学が活用されている.データ科学という学問体系自身の発展に寄与する研究も重要であるが,様々な学問領域を持つ本学では教員・学生自身の専門領域においてデータ科学の知見を用いることによる新たな知の創造もまた重要なミッションの一つである.
データ科学センターはこの立場からグローバル・エデュケーション・センターと協力して全学部・研究科向けに「データ科学教育プログラム」を提供している.
人文社会系・理工系を問わず様々な学問領域や数理的なバックグラウンドの異なる学生に対して,各自が自身の学問領域においてデータ科学の知見を活かすことを目的としている.
最も重要な特徴としては統計学や機械学習などの分野で個別に発展してきた手法を意思決定の目的という観点から整理,データ科学を統一的な視点で体系的に学べるプログラムとなっている点である.これにより自身の学問領域においてデータ科学の知見を活かすための考え方を見通しよく学ぶことができる.
科目の特徴:全学部・研究科の学生に対してフルオンデマンド科目として提供されており,場所や時間を選ばずに本学の学生であれば誰でも受講可能となっている.また各回においてプログラミング言語を用いた演習を用意しており,分野を問わず必要となるデータ科学の理論を学ぶだけでなく,実際のデータを取り扱うためのスキルも同時に学ぶ構成となっている.
