A Novel Visual Cue-Based Multi-Modal Turn-Taking Model for Speaking Systems
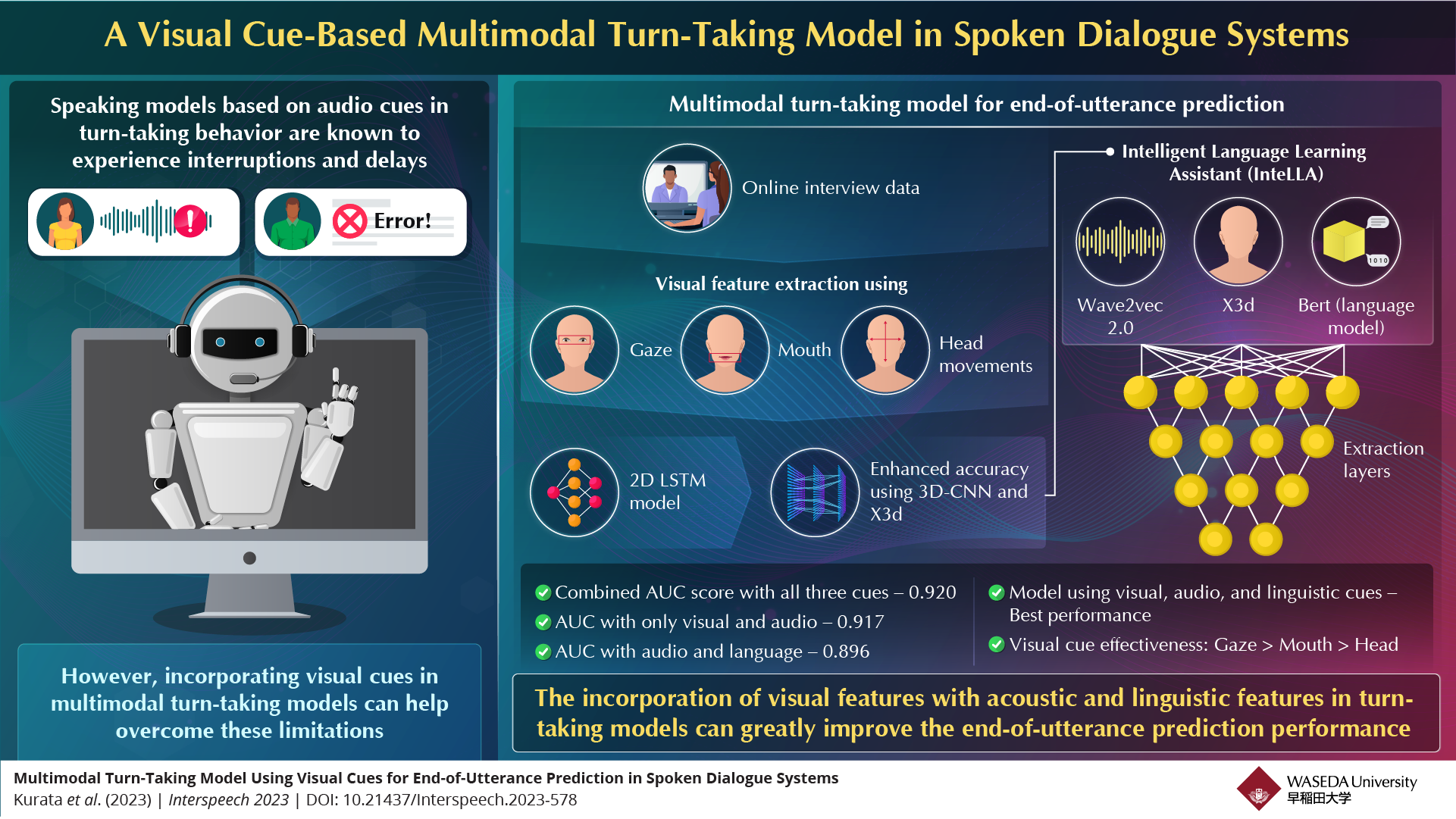
Traditional speaking systems that incorporate turn-taking behaviour during interviews typically rely on language and sound to decide when a person’s turn ends, and the other person’s turn begins. While these cues have been effective, these models still suffer from interruptions and long delays between turns. Many studies have suggested that visual cues, such as eye gaze, mouth, and head movements as well as gestures can effectively help in improving the accuracy of turn-taking models.
To test this idea, a team of researchers led by Associate Research Professor Yoichi Matsuyama of Waseda University has now investigated how specific visual cues could enhance turn-taking models in conversations, especially during interviews. The team then used these findings to develop a novel turn-taking model for end-of-utterance prediction during interviews.
They first developed a turn-taking model using a two-dimensional convolutional neural network (CNN), called long-short-term memory (LSTM), incorporating gaze, mouth, and head movements and conducted an ablation study — a set of experiments in which components of a system are removed/replaced in order to understand its impact on the performance of the system.
The team used data from online interviews consisting of 10 minutes of dialogue between a Japanese English learner and an English teacher to investigate the model. The results revealed that the model with all three visual cues demonstrated the best performance. Moreover, it also revealed that gaze had the most significant impact on performance, followed by mouth movements.
Next, to capture these visual cues more accurately, they developed a more advanced end-to-end visual extraction model, utilizing a three-dimensional CNN, called X3d. This model, owing to its higher accuracy in capturing visual information, demonstrated higher performance and accuracy compared to the LSTM model.
Finally, they used this improved visual extraction model to develop a multi-modal turn-taking speaking model, called Intelligent Language Learning Assistant (InteLLA). InteLLA utilizes the Wave2vec model for incorporating acoustic cues, X3d for visual cues and the Bert language model for linguistic cues. Each of these models can be used independently for turn-taking cues.
Further, the team compared the performance of InteLLA for all combinations of acoustic, linguistic, and visual features. The results revealed that using all three features resulted insignificant improvement in performance, compared to using only acoustic and linguistic cues.
This innovative system, with its focus on visual cues, has the potential to achieve natural conservations, like human interviewers. It has applications in various fields from language proficiency courses to individual self-learning.
This study has received a prestigious award called the “ISCA Award for Best Student Paper” at Interspeech, the world’s largest international conference on spoken language processing in August 2023.
Link to the original journal article: https://www.isca-speech.org/archive/interspeech_2023/kurata23_interspeech.html
About the author
Dr. Yoichi Matsuyama is the Founder and CEO of Equmenopolis, Inc. and is currently an Associate Research Professor at the Perceptual Computing Laboratory, Waseda University, Tokyo. Prior to this, he was working as a Post Doctoral Fellow (Special Faculty) in the ArticuLab in the School of Computer Science, Carnegie Mellon University. He received a B.A. in cognitive psychology and media studies, and an M.E. and Ph.D. in computer science from Waseda University in 2005, 2008, and 2015 respectively. His research interest lies in the field of computational models of human conversations, which combine artificial intelligence, social science, and human-computer/robot interaction.
LANGX Speaking, a conversation-based English proficiency assessment system.
A team of researchers led by Yoichi Matsuyama developed a conversational AI-based system to determine a learner’s English conversation and communication skills. It has been officially adopted for Tutorial English, a Waseda University regular course class, starting from the 2023 academic year.
Title of the paper: Multimodal Turn-Taking Model Using Visual Cues for End-of-Utterance Prediction in Spoken Dialogue Systems
Journal: INTERSPEECH 2023
Authors: Fuma Kurata, Mao Saeki, Shinya Fujie, and Yoichi Matsuyama
DOI: 10.21437/Interspeech.2023-578






