
量的テキスト分析とは何か
量的テキスト分析とは、私たちが普段使っている言葉「自然言語」をコンピュータで処理し、社会・人文科学的な情報を抽出する手法です。私の専門である政治コミュニケーションの研究でいえば、選挙マニフィストを通じての、候補者の政治的イデオロギーの推定や、政治家のスピーチ分析、新聞記事に隠された政治的偏向の発見などに利用されます。他にも量的テキスト分析は、テーマに即した図書の分類や、変わったところでは匿名で発表された文学作品の著者探しなどにも使われています。
自然言語処理の研究は、世界大戦中の暗号解読技術の応用としての、自動翻訳の研究に始まりました。1990年代に入り、コンピュータの性能の向上とともに、電子的データの増加やインターネットの登場によって、技術は飛躍的に発展し、大規模なテキストデータの統計的な分析手法が確立しました。2000年代初頭から今日にかけて、さまざまな量的テキスト分析に利用できる機械学習モデルが開発され、発展しつつあります。
量的テキスト分析のツールQuantedaの開発
私はロンドン政治経済学学院(LSE)で博士号を取得し、その後、2018年に帰国するまで研究員として勤めていました。その間、そして現在もR言語におけるテキスト分析パッケージQuanteda(Quantitative Analysis of Textual Dataの略)の開発に携わっています。
Quantedaは、LSEのKenneth Benoitが欧州研究会議の支援を受けて、2012年から開発に着手した量的テキスト分析のためのツールで、今年(2018年)1月にバージョン1.0が発表されました。テキスト分析のためには、これまでさまざまなソフトウェアが開発されてきましたが、多機能かつ効率的なものはありませんでした。
Quantedaは現段階でも、先行するRパッケージの「tm」や「tidytext」、Pythonパッケージの「gensim」よりも多機能で、処理速度やメモリ使用量の点でも優れ、文系の研究者にも使いやすく、北米およびヨーロッパの主導的な政治学者の支持を得ています。
さらに、Quantedaの他と大きく異なる点として、全ての言語を扱えるユニコードに準拠するため、中国語・日本語・韓国語などのアジア言語にも対応可能だということがあげられます。英語圏の研究者と同じ道具を使い、同じモデルを使って分析することで、国際比較も可能ですし、トップジャーナルに発表できる。日本をはじめ、アジア人研究者のQuantedaへの期待は大きいと思います。

アメリカに対する他国の認識の変化を新聞記事から分析する
Quantedaを使い、アメリカに対する他国の認識が、アメリカ国内の政治状況とどのように相関しているかを過去30年にわたる日本と英国の新聞記事で分析しました。
日英の記事データベースで、(「アメリカ」OR「US」 AND (「政府」OR「政治」OR「外交」OR「軍事」)でキーワード検索を行い、抽出された朝日新聞14万1746件、ガーディアン紙17万6399件の記事がどのようにアメリカを報道したかを、フレーミングの観点から準教師あり空間ベクトルモデル(Latent Semantic Analysis)を用いて計量に分析しています。
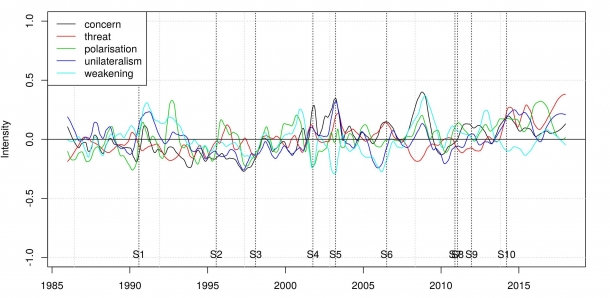
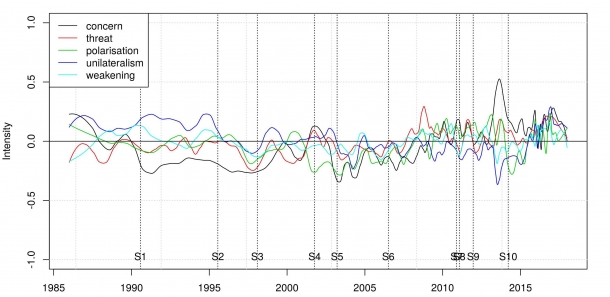
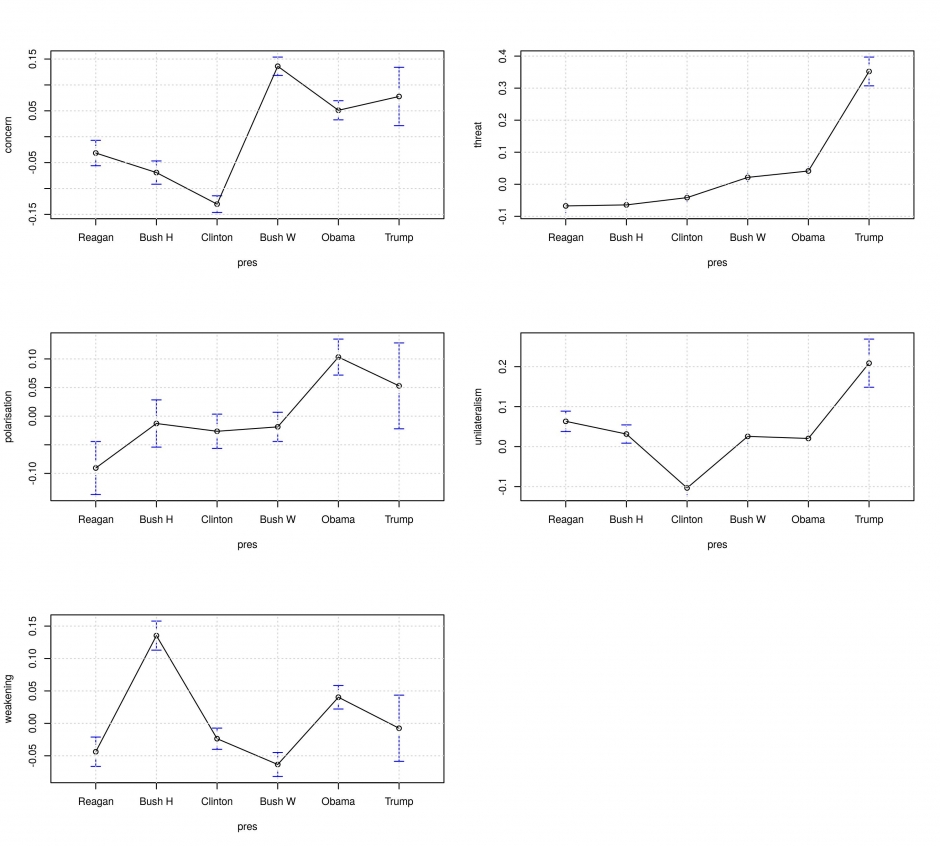
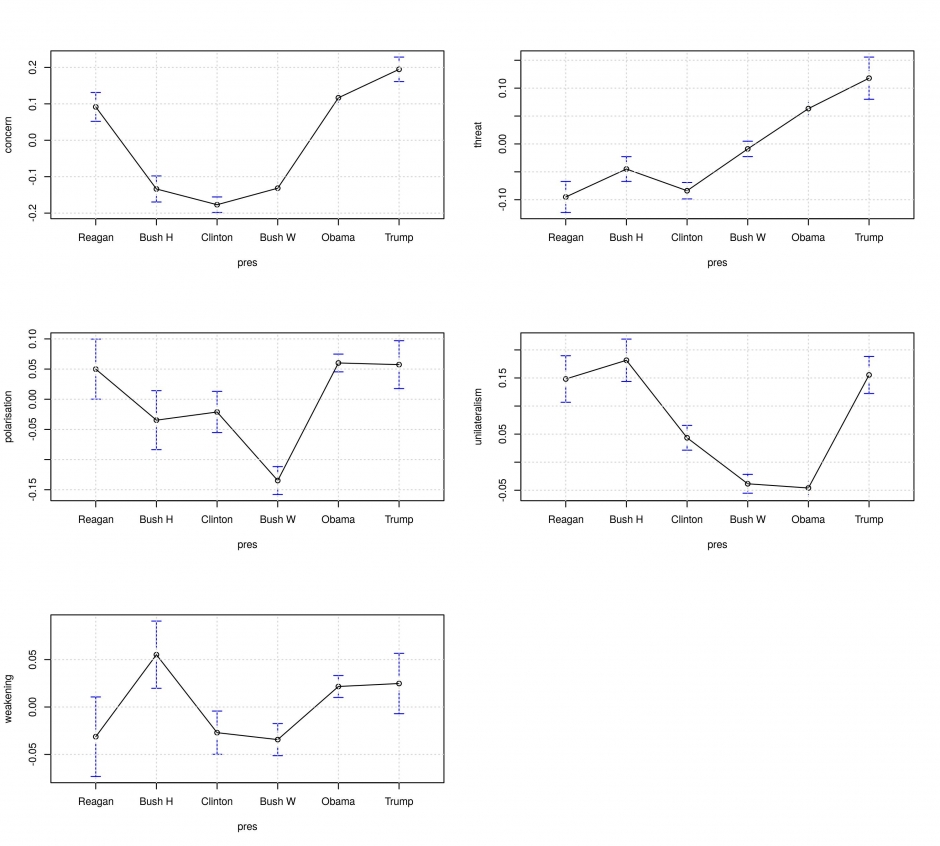
測定された値を、レーガン(1981~1988年)、Hブッシュ(1989年から1993年)、クリントン(1993~2001年)、Wブッシュ(2001~2009年)、オバマ(2009~2017年)、トランプ(2017年~)の任期ごとに平均すると、30年間の間にアメリカのとらえ方がどのように変化したかがよくわかります。
ネットを利用したロシアの国際プロパガンダ戦略を分析する
もう一つのQuantedaを使った研究事例は、ロシア国営のウェブサイト「スプートニクニュース」(https://sputniknews.com/)の記事分析です。スプートニクニュースには、日本語を含め、英語、スペイン語、フランス語、ドイツ語など30か国語以上の編集部が存在しています。
2017年7月以降にこのサイトに登場した英語の記事51,651件を経済、政治、社会、外交、軍事、自然の6トピックに分類し、それぞれの次のようなキーワードで抽出しました。
| Topic | Seed words |
| economy | market*, money, bank*, stock*, bond*, industry, company, shop* |
| politics | parliament*, congress*, party leader*, party member*, voter*, lawmaker*, politician* |
| society | police, prison*, school*, hospital* |
| diplomacy | ambassador*, diplomat*, embassy, treaty |
| military | military, soldier*, air force, marine, navy, army |
| nature | water, wind, sand, forest, mountain, desert, animal, human |
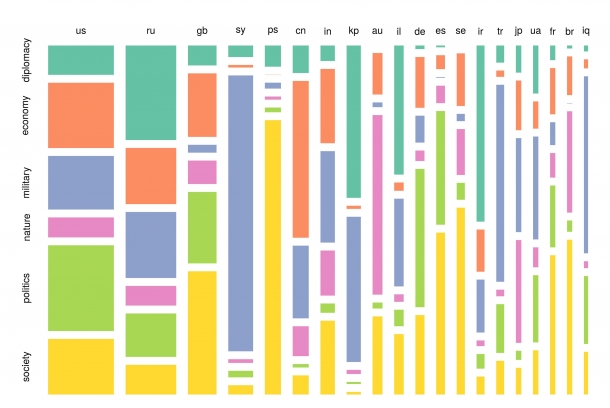
以下のグラフが、国別に取り上げられた記事のカテゴリー分類です。
アメリカ(us)やイギリス(gb)で社会(society)と政治(politics)に関する記事が多いのは、スプートニクニュースが、この二つの国を標的としてプロパガンダを行っているからです。反対に日本(jp)で、自然(nature)が若干大きくなっているのは、原子力などの環境関連の記事が多いからです。シリア(sy)やアフガニスタン(af)のトピックとして軍事(military)が大きく取り上げられていることは当然ですが、スウェーデン(se)のトピックSocietyが大きくなっているのは、ロシアのスウェーデンを北大西洋条約機構に加入させないようにする意図を感じさせます。この研究は、8月のドイツのハンブルグで開催されたECPRの学会で発表しました。
メディアと量的テキスト分析の今後
私の本来の専門はメディア研究です。いわゆるフェイクニュースが拡散し、新聞の党派性が高まるなど、メディアを放っておくと、この先私たちの情報環境はどんどん悪い方向にいくでしょう。それを止めるために、より多くの研究者がさまざまな観点から分析を行い、何がおかしいと指摘しなければいけないと思っています。
その点からも、大規模コンピュータや巨大なマンパワーを使わずとも、毎日大量に生まれ続けるデータを効率的に処理する「個人が使える道具」としてのQuantedaの開発に意義を感じています。
取材・構成:山本綾子
協力:早稲田大学大学院政治学研究科J-School







